Qualitative Data and QualCoder
Last updated on 2025-07-11 | Edit this page
Estimated time: 60 minutes
Overview
Questions
- What can we learn from existing qualitative data?
- How is qualitative interview data typically structured?
- How can documents and projects be imported into QualCoder?
Objectives
- Practice finding and downloading data from a qualitative data repository
- Create a QualCoder project
- Practice importing and organizing documents
For decades, a movement has been building among quantitative researchers to share data and analysis as completely as possible. In part, this is meant to improve scientific transparency, so findings can be checked and verified, but it also serves to provide a basis for future studies.
Qualitative researchers have been much slower to adopt data and analysis sharing, for a few different reasons, including both technical and normative constraints. On the technical side, qualitative data has had limited standards, and analysis has often been conducted manually or with specialized software with limited compatibility with other software. More importantly, however, qualitative researchers tend to emphasize the role of both the context of data collection and the perspective of the researcher in the research process - in contrast to quantitative methods that often seek precisely to minimize the subjectivity of their methods and draw wide-ranging conclusions about entire populations.
Moreover, qualitative data often presents challenges for protecting privacy when sharing data, because interviews, focus groups, and other qualitative methods provide rich detail that can make it easier to identify participants even if direct identifiers are removed, as well as often dealing with sensitive issues.
Despite these challenges, however, there is a small but growing movement to share and reuse qualitative and mixed methods data and analysis, helped along by recent technical developments.
In this lesson, we will start by exploring what advantages sharing and reusing qualitative research can offer that might offset the challenges it presents, then practice finding, reusing, and sharing data and analysis projects with the largest qualitative data archive, QDR, and the most widely used coding and qualitative data analysis software, NVivo.
The data we will work with are real data, although the scenario we use is somewhat artificial. Our goal is twofold - to help build literacy and skills for working with secondary qualitative data using relevant tools and to help develop an imagination for how you might reuse and share qualitative and mixed methods data to improve your own research.
Reusing Qualitative Data
The first step to reuse is to understand what elements might be reused and why. Historically, research products like articles and books have been the primary shared output of qualitative research. However, there are at least four other common research products that may be valuable for reuse or adaptation:
- methodologies and data collection instruments
- raw or processed (i.e. transcribed or summarized) data
- codebooks
- analysis
In the next step, we’ll download some real qualitative data and explore how each of these products might be useful to another researcher.
Types of data
Throughout this lesson, we’ll be using semi-structured interviews, one of the most common types of qualitative data, in our examples and discussion. Content analysis generally involves similar concerns and processes, but uses other kinds of secondary data, such as published print or audio-visual materials. Other qualitative methods, such as participant observation and focus groups, may be somewhat less suited to these tools and approaches and may require adaptation beyond what is discussed here.
Part of the power of qualitative research is its recognition that no method can be truly universal and that all analysis is contextual. We encourage you to treat the discussion and tools here as starting points, rather than templates.
Finding and Downloading QDR Data
Discussing data reuse in the abstract can only get you so far. Instead, we will imagine we face the following scenario and working together to discover how we can take advantage of others hard work to improve our research:
You are preparing to conduct a study of social media users in multiple countries, with a focus on understanding how people make decisions about the privacy of their posts and profiles.
Participants will complete brief surveys about their demographic background, participate in one or more semi-structured interviews, and provide access to their posts on each platform they regularly use for a period of 1 month. You are the lead researcher, but are joined by both long-term collaborators and student research assistants, who are likely to come and go throughout the expected duration of the research.
Your training in qualitative research makes you skeptical of the value of data that was collected for other purposes, but you also know you won’t have much time to collect the data and need to ensure you make the most of the opportunity and structure your interviews so they can reveal critical findings.
One of your collaborators referenced a dissertation that used qualitative methods to study data sharing in qualitative and big social research, and you noticed that the dissertation mentioned that anonymized data are available online. Although your research questions differ from theirs, you wonder if their interviews might help guide how you approach your study and decide to take a look.
The first step to finding out whether this data can help is to get the data.
Following the link in the dissertation, visit the data’s summary page at the Qualitative Data Repository, or QDR. QDR describes itself as
…a dedicated archive for storing and sharing digital data (and accompanying documentation) generated or collected through qualitative and multi-method research in the social sciences and related disciplines.
Essentially, QDR is a place for researchers to share qualitative and mixed methods data in a variety of forms, as well as their analysis projects. Some data are restricted and require an application or agreement before using, but other data, including what we are interested in, are openly available to any registered user.
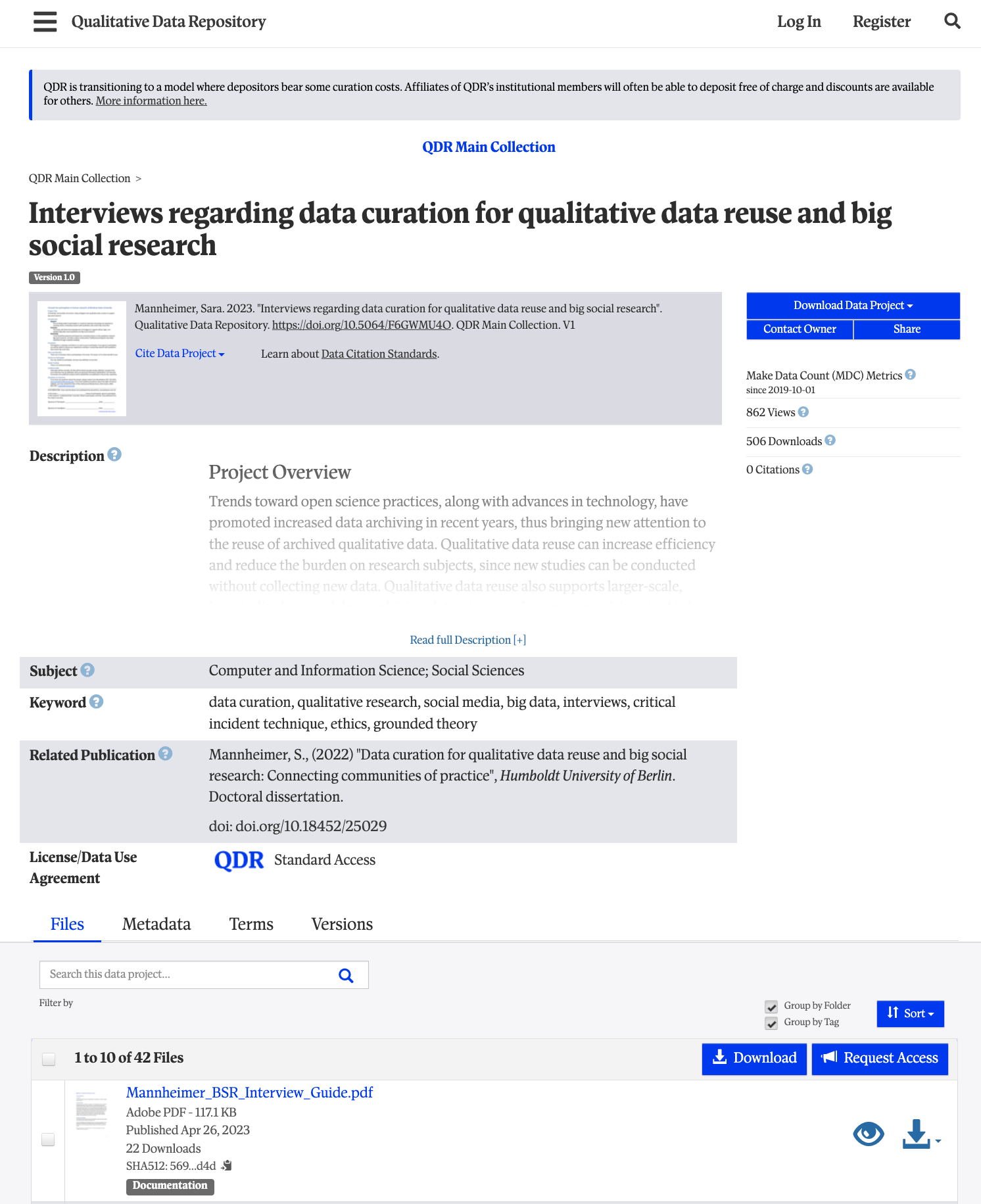
This project contains a wide variety of information, including:
- interview transcripts from three different populations
- interview analysis
- participant summaries
- interview guides
- study documents (consent forms, solicitations, IRB)
Both the topic and the range of data available seem promising, and the QDR Standard Access license agreement allows any registered user to download the data, so let’s download it and see what we find!
If you don’t already have one, you’ll need to create an account at
QDR for the next step. To do so with your email, click Register. in the top right
of the summary page. Alternatively, you can use an ORCID or Google
account to register by clicking Login and finding the
appropriate option. Fill out the registration form and click
Create new account, performing any necessary verification
before proceeding.
QDR or your local internet network may be overwhelmed if larger
groups download the full project simultaneously. For this workshop, you
may choose to have learners instead exclude the NVPX (NVivo) file, which
will reduce the download size by around 95%. To do this: 1. Check the
box at the top-left of the file list (below the project description). 2.
Click select all 42 files in this data project. 3. Scroll
to the bottom of the list, navigate to the last page, and uncheck the
NVPX file 4. Click Download
Alternatively, learners can select only the files that will be used in the workshop. This is the most efficient but least like common data reuse patterns, where researchers won’t necessarily know which raw datafiles have the information of interest to them.
List of files for workshop:
- README_Mannheimer.txt
- Mannheimer_BSR01_Transcript.pdf
- Mannheimer_BSR02_Transcript.pdf
- Mannheimer_BSR05_Transcript.pdf
- Mannheimer_Redacted_Interview_Analysis.qdpx
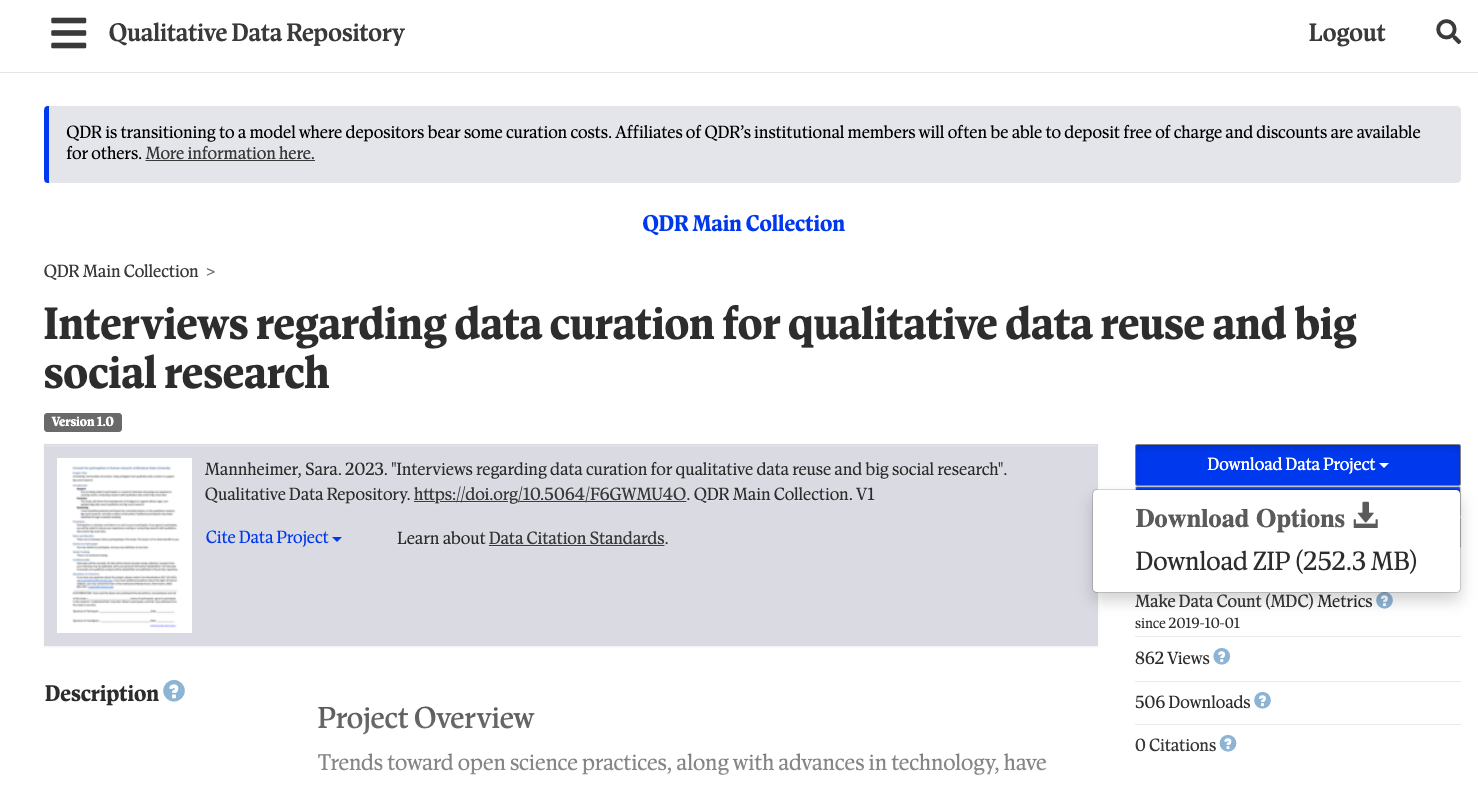
Once you have a QDR account, log in with the button on the top right
and return to the [summary page][mannheimer-qdr]. Click
Download Data Project (see image below), download the ZIP
file to your desktop, and extract the files into a folder on your
desktop.
File types
Open the folder using Finder (Mac) or
Explorer (Windows) and inspect the file extensions
(the part after the . in the filename). What types of files
are included and what software would typically be used to open them?
Don’t worry if you don’t recognize all of the file types. Just
identify what you know. If you have time during the exercise, you can
use a web search like txt extension to search for
information.
The project includes the following four types of files:
-
txtfiles are plain text and can be opened in any notepad or document software -
pdffiles can be opened withAdobe Readeror other document software -
nvpxfiles are NVivo for Mac projects and can only be opened in NVivo for Mac or converted in NVivo for Windows to a Windows format -
qdpxfiles are the REFI-QDA qualitative interchange format and can be opened in a variety of qualitative software
In this project, the txt files provide
metadata, or information about the project, while all other
files are part of the data itself. QualCoder can’t read
nvpx files, so the most important files to us will be the
pdf interview transcripts and the qdpx project
file.
Creating a QualCoder Project
Once we have a general sense of the data we’ll be using and what format it needs to be in, the next step is generally to create a project in a qualitative software package and import the de-identified raw data.
QualCoder is an open-source and cross-platform tool for coding and analysis of textual data. It is capable of working with a variety of data formats and has tools for both qualitative and mixed methods analysis.
Qualitative software is sometimes called CAQDAS or QDAS, an acronym for Coding and Qualitative Data Analysis Software to recognize the two essential functions of qualitative research software:
- Apply codes or tags systematically to a collection of data sources
- Analyze codes (and sometimes raw data or secondary sources) to draw conclusions
CAQDAS have various features that may be useful for particular types of data or methodologies. This lesson includes an alternative software options page for those interested in learning about other CAQDAS.
Starting QualCoder
If you haven’t already installed QualCoder, please follow the instructions in [Summary and Setup][../index.html] before proceeding.
When you first open QualCoder, it will display the
Action Log tab with some information about project settings
and any currently-open projects, like the example below.
Creating a project
Work in QualCoder is organized in projects, each of which contain
their own sets of files, codes and other information.
Click Project - Create New Project and, after choosing a
location where you can easily find it later (like your
Desktop) give the project a clear name like
Social_media_privacy_project_planning. This creates a new
folder whose name ends in .qda so QualCoder can identify it
easily as a project.
Clicking Save returns us to the action log, which now
displays a summary of the new project.
Importing and navigating files
Now that we have a QualCoder project, let’s take a look at what the
original data contains. QDAS projects store copies of sources within
their directory. To see the project description, we’ll first need to
import README_Mannheimer.txt into our project.
Documents can be imported with the Manage - Manage Files
command. Add README_Mannheimer.txt by clicking on the
Page icon with a + or pressing
CTRL/CMD+2.
In collections of data or other multi-file downloads, there is often
a file named readme.txt or something similar. These are
meant to provide an overview of the collection and how to go about using
them.
To view the contents of the file, open Code text from
the Coding menu at the top-left then click on the name of
the file you just imported at the left. Zero in on the first paragraph
under Data Description and Collection Overview:
The data in this study was collected using semi-structured interviews that centered around specific incidents of qualitative data archiving or reuse, big social research, or data curation. The participants for the interviews were therefore drawn from three categories: researchers who have used big social data, qualitative researchers who have published or reused qualitative data, and data curators who have worked with one or both types of data. Six key issues were identified in a literature review, and were then used to structure three interview guides for the semi-structured interviews. The six issues are context, data quality and trustworthiness, data comparability, informed consent, privacy and confidentiality, and intellectual property and data ownership.
This short paragraph packs a great deal of information about the interview topics and questions. Our topic of social media privacy may share a good deal with some of the issues the original interviews focused on.
For now, we’re going to focus on the Big Social Research group, because the type of data they were interviewed about their work with is the most similar to what our participants may be sharing. You may have drawn a different conclusion, and likewise, each group might provide unique insights.
If we can adapt questions and anticipate concerns and challenges relevant to our data collection, we may be able to improve the quality of our study and interview design, without repeating all the background research from the previous study.
Raw Data
Interview schedules and study plans provide insight into the research team’s expectations and approaches. The power of raw data, such as interview transcripts, is that it shows (much more directly) how the study participants construct their own views of the study topics and respond to the questions. Context and constructivism are core concerns of most qualitative researchers, lending the raw data possibly the most critical aspect of data for faithful and effective reuse.
It’s possible to conduct entirely secondary studies if enough raw data are available in relevant context that address relevant topics. Often, however, existing data serves as a type of pilot study - providing initial evidence as to where to begin and what to ask while still allowing the new research team to explore aspects of the data that were less relevant or highlighted in the original study.
One of the most commonly-analyzed types of raw qualitative data is interview transcripts, like we have in our project. QualCoder provides support for working directly with audio and video files. Text, however, is often preferred because it simplifies the process of removing potentially identifying information and enables both rapid scanning of content and accessibility technology.
Let’s open one of the Big Social transcripts,
Mannheimer_BSR01_Transcript.pdf, in your default
PDF reader (not QualCoder) and look at how transcripts are
structured in this project.

PDF files appear as page images, but most modern PDFs
allow you to select text and other elements. In this transcript, we see
a few header elements:
- The document title
- A set of summary keywords identified by the original investigators as relevant to this interview
- A list of all speakers
After the speaker list, the transcript itself begins with each paragraph denoting a switch in speaker. The speaker’s identifier and a time stamp for the start of the conversation comprise the first line, followed by the transcribed text.
Reading even this first section in the image, we can get some insight
into decisions the research team made and how they worked. From
BSR01’s very first sentence, we see the researchers sent a
list of interview questions in advance but with mixed results:
I haven’t looked at the questions you sent. Yeah, but this is an active project. So I don’t think I should have a problem with any of them.
The respondent may not have read all the questions but did identify a project that the rest of the interview will revolve around.
Import additional files
Import the following three files into QualCoder, then open the
BSR_01 transcript and compare the formatting in the preview
to what it looked like in the original PDF.
Files to import
- Mannheimer_BSR01_Transcript.pdf
- Mannheimer_BSR02_Transcript.pdf
- Mannheimer_BSR05_Transcript.pdf
QualCoder converts all text and PDF documents to plain text when importing, which removes formatting and visual elements. The QualCoder Wiki provides guidance on how to pre-convert PDFs to a text format if you experience readability problems.
In general, the best results will come from importing text documents in text (TXT/RTF), Word (DOC/DOCX), or webpage (HTM/HTML) formats rather than PDF.
Documents can also be created and edited in QualCoder, but its interface is not optimized for significant edits. In general, any changes, including the removal of personally identifiable information from data that will be shared, should take place before they are added to the project.
In the next section of the workshop, we will develop multiple kinds of qualitative codes and apply them to the interviews you just imported in QualCoder.
- Qualitative data can take many forms, but text or transcribed audio-visual data are among the most common
- Reusing existing qualitative data can help plan studies more efficiently and effectively
- The Qualitative Data Repository is a source for vetted qualitative and mixed methods data
- QualCoder’s interface has sections for managing various aspects of projects and uses a mix of icons, menus, and pop-up windows to perform actions